Archive for the ‘technology’ Category
is 2020 the “drop your tools” and “do-ocracy” epoch?
In Karl Weick’s (1996) analysis of the Mann Gulch disaster and a similar fire at South Canyon, he differentiates the organizational conditions under which some smoke jumpers survived, while others died when wildfires suddenly turned. According to Weick, the key turning point between survival and death was the moment when one firefighter ordered others in his team to “drop your tools.” Among other organizing challenges, this order to leave expensive equipment violated smoke jumpers’ routines, even their central identities as smoke jumpers. Indeed, some did not comply with this unusual order to abandon their tools, until others took their shovels and saws away. Post-mortem reports revealed how smoke jumpers who perished were still wearing their heavy packs, with their equipment still at their sides. Those who shed their tools, often at the urging of others, were able to outrun or take shelter from the wildfires in time. Weick’s introduction states,
“Dropping one’s tools is a proxy for unlearning, for adaptation, for flexibility…It is the very unwillingness of people to drop their tools that turns some of these dramas into tragedies” (301-302).
Around the world, some organizations, particularly those in the tech and finance industries, were among the first to enact contingency plans such as telecommuting and spreading workers out among sites. Such steps prompted consternation among some about the possible meaning and aims of such actions – is the situation that serious? Is this just an opportune moment for surveilling more content and testing outsourcing and worker replaceability? What does all this mean?
Meanwhile, other organizations are investing great efforts to continue regular topdown, operations, sprinkled in with the occasional fantasy planning directives. (Anyone who has watched a class of undergraduates and then a class of kindergarteners try not to touch their faces will quickly realize the limits of such measures.) Without the cooperation of organizations and individual persons, critics and health professionals fear that certain organizations – namely hospitals and the medical care system – can collapse, as their operations and practices are designed for conditions of stability rather than large, sustained crises.
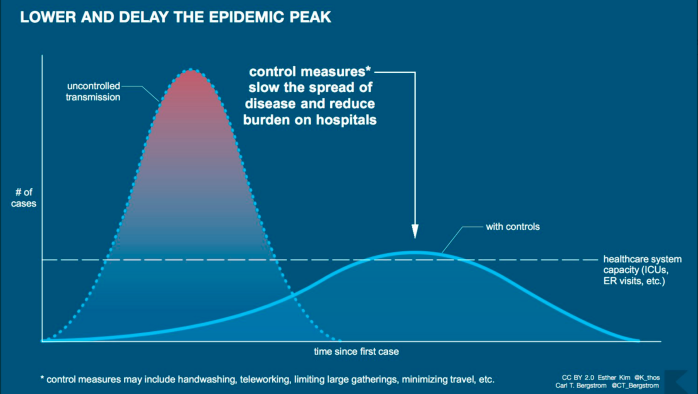
For organizational researchers like myself, these weeks have been a moment of ascertaining whether organizations and people can adapt, or whether they need some nudging to acknowledge that all is not normal and to adjust. At an individual level, we’re all facing situations with our employers, voluntary organizations, schools and universities, and health care for the most vulnerable.
For the everyday person, the realization that organizations such as the state can be slow to react, and perhaps has various interests and constraints that inhibit proactive instead of reactive actions, may be imminent. So, what can compensate for these organizational inabilities to act? In my classes, I’ve turned towards amplifying more nimble and adaptive organizational forms and practices. Earlier in the semester, I’ve had students discuss readings such as the Combahee River Collective in How We Get Free (2017, AK Press), to teach about non- and less- bureaucratic options for organizing that incorporate a wider range stakeholders’ interests, including ones that challenge conventional capitalist exchanges.
To help my undergraduates think through immediately applicable possibilities, I recently assigned a chapter from my Enabling Creative Chaos book on “do-ocracy” at Burning Man to show how people can initiate and carry out both simple and complex projects to meet civic needs. Then, I tasked them with thinking through possible activities that exemplify do-ocracy. So far, students have responded with suggestions about pooling together information, supplies, and support for the more vulnerable. One even recommended undertaking complex projects like developing screening tests and vaccines – something, that if I’ve read between the lines correctly, well-resourced organizations have been able to do as part of their research, bypassing what appears to be a badly-hampered response CDC in the US.
(For those looking for mutual aid-type readings that are in a similar vein, Daniel Aldrich’s Black Wave (2019, University of Chicago Press) examines how decentralized efforts enabled towns in Japan to recover more quickly from disasters.)
Taking a step back, this period could be one of where many challenges, including climate change and growing inequality, can awaken some of us to our individual and collective potential. Will be this be the epoch where we engage in emergent, interdependent activities that promote collective survival? Or will we instead suffer and die as individuals, with packs on our backs, laden down with expensive but ultimately useless tools?
book spotlight: beyond technonationalism by kathryn ibata-arens
At SASE 2019 in the New School, NYC, I served as a critic on an author-meets-critic session for Vincent de Paul Professor of Political Science Kathryn Ibata-Arens‘s latest book, Beyond Technonationalism: Biomedical Innovation and Entrepreneurship in Asia.

Here, I’ll share my critic’s comments in the hopes that you will consider reading or assigning this book and perhaps bringing the author, an organizations researcher and Asia studies specialist at DePaul, in for an invigorating talk!
“Ibata-Arens’s book demonstrates impressive mastery in its coverage of how 4 countries address a pressing policy question that concerns all nation-states, especially those with shifting markets and labor pools. With its 4 cases (Japan, China, India, and Singapore), Beyond Technonationalism: Biomedical Innovation and Entrepreneurship in Asia covers impressive scope in explicating the organizational dimensions and national governmental policies that promote – or inhibit – innovations and entrepreneurship in markets.
The book deftly compares cases with rich contextual details about nation-states’ polices and examples of ventures that have thrived under these policies. Throughout, the book offers cautionary stories details how innovation policies may be undercut by concurrent forces. Corruption, in particular, can suppress innovation. Espionage also makes an appearance, with China copying’s Japan’s JR rail-line specs, but according to an anonymous Japanese official source, is considered in ill taste to openly mention in polite company. Openness to immigration and migration policies also impact national capacity to build tacit knowledge needed for entrepreneurial ventures. Finally, as many of us in the academy are intimately familiar, demonstrating bureaucratic accountability can consume time and resources otherwise spent on productive research activities.
As always, with projects of this breadth, choices must made in what to amplify and highlight in the analysis. Perhaps because I am a sociologist, what could be developed more – perhaps for another related project – are highlighting the consequences of what happens when nation-states and organizations permit or feed relational inequality mechanisms at the interpersonal, intra-organizational, interorganizational, and transnational levels. When we allow companies and other organizations to, for example, amplify gender inequalities through practices that favor advantaged groups over other groups, what’s diminished, even for the advantaged groups?
Such points appear throughout the book, as sort of bon mots of surprise, described inequality most explicitly with India’s efforts to rectify its stratifying caste system with quotas and Singapore’s efforts to promote meritocracy based on talent. The book also alludes to inequality more subtly with references to Japan’s insularity, particularly regarding immigration and migration. To a less obvious degree, inequality mechanisms are apparent in China’s reliance upon guanxi networks, which favors those who are well-connected. Here, we can see the impact of not channeling talent, whether talent is lost to outright exploitation of labor or social closure efforts that advantage some at the expense of others.
But ultimately individuals, organizations, and nations may not particularly care about how they waste individual and collective human potential. At best, they may signal muted attention to these issues via symbolic statements; at worst, in the pursuit of multiple, competing interests such as consolidating power and resources for a few, they may enshrine and even celebrate practices that deny basic dignities to whole swathes of our communities.
Another area that warrants more highlighting are various nations’ interdependence, transnationally, with various organizations. These include higher education organizations in the US and Europe that train students and encourage research/entrepreneurial start-ups/partnerships. Also, nations are also dependent upon receiving countries’ policies on immigration. This is especially apparent now with the election of publicly elected officials who promote divisions based on national origin and other categorical distinctions, dampening the types and numbers of migrants who can train in the US and elsewhere.
Finally, I wonder what else could be discerned by looking into the state, at a more granular level, as a field of departments and policies that are mostly decoupled and at odds. Particularly in China, we can see regional vs. centralized government struggles.”
During the author-meets-critics session, Ibata-Arens described how nation-states are increasingly concerned about the implications of elected officials upon immigration policy and by extension, transnational relationships necessary to innovation that could be severed if immigration policies become more restrictive.
Several other experts have weighed in on the book’s merits:
“Kathryn Ibata-Arens, who has excelled in her work on the development of technology in Japan, has here extended her research to consider the development of techno-nationalism in other Asian countries as well: China, Singapore, Japan, and India. She finds that these countries now pursue techno-nationalism by linking up with international developments to keep up with the latest technology in the United States and elsewhere. The book is a creative and original analysis of the changing nature of techno-nationalism.”—Ezra F. Vogel, Harvard University
“Ibata-Arens examines how tacit knowledge enables technology development and how business, academic, and kinship networks foster knowledge creation and transfer. The empirically rich cases treat “networked technonationalist” biotech strategies with Japanese, Chinese, Indian, and Singaporean characteristics. Essential reading for industry analysts of global bio-pharma and political economists seeking an alternative to tropes of economic liberalism and statist mercantilism.”—Kenneth A. Oye, Professor of Political Science and Data, Systems, and Society, Massachusetts Institute of Technology
“In Beyond Technonationalism, Ibata-Arens encourages us to look beyond the Asian developmental state model, noting how the model is increasingly unsuited for first-order innovation in the biomedical sector. She situates state policies and strategies in the technonationalist framework and argues that while all economies are technonationalist to some degree, in China, India, Singapore and Japan, the processes by which the innovation-driven state has emerged differ in important ways. Beyond Technonationalism is comparative analysis at its best. That it examines some of the world’s most important economies makes it a timely and important read.”—Joseph Wong, Ralph and Roz Halbert Professor of Innovation Munk School of Global Affairs, University of Toronto
“Kathryn Ibata-Arens masterfully weaves a comparative story of how ambitious states in Asia are promoting their bio-tech industry by cleverly linking domestic efforts with global forces. Empirically rich and analytically insightful, she reveals by creatively eschewing liberalism and selectively using nationalism, states are both promoting entrepreneurship and innovation in their bio-medical industry and meeting social, health, and economic challenges as well.”—Anthony P. D’Costa, Eminent Scholar in Global Studies and Professor of Economics, University of Alabama, Huntsville
“organized creativity: approaching a phenomenon of uncertainty” spring school 2019 at Freie Universität Berlin, Germany – cfp due Oct. 15, 2018

Photo credit: Banksy instagram
Are you researching a phenomena like this?
Are you looking for a trans-Atlantic research community to share your research on creativity? Please download INTERNATIONALSPRINGSCHOOLOC_2019CALL.korr. Or, read the copied and pasted cfp below:
“Organized Creativity: Approaching a Phenomenon of Uncertainty
INTERNATIONAL SPRING SCHOOL, MARCH 12-15, 2019,
Freie Universität Berlin, Germany
Call for Papers
Creativity is one of the key concepts, yet among the most slippery ones of present-day Western societies. Today, the call for creativity spans far beyond typically “creative” fields and industries towards becoming a universal social norm. Creative processes, however, are fundamentally surrounded by uncertainty. It is difficult to know ex-ante what will become a creative idea and, due to its destructive force, it is also highly contested. This inherent uncertainty associated with creativity thus spills over to other social spheres, too.
The DFG-funded Research Unit “Organized Creativity” is studying creative processes in music and pharmaceuticals – as representatives for creativity in the arts and in the sciences. The goal of the unit is to understand in greater depth those practices of inducing and coping with uncertainty which are employed by various actors involved in creative processes.
Target Group
The Spring School provides space for exchange between advanced doctoral students, early postdocs and several senior scholars that do research on creativity either in the context of innovation research or in the fields of business and management studies, economic geography, psychology or sociology. Combining lectures from renowned scholars (Prof. Dr. Dr. Karin Knorr Cetina, Prof. David Stark, Ph.D., Prof. Dr. Gernot Grabher, Prof. Dr. Elke Schüßler, Prof. Dr. Jörg Sydow) with the presentation, discussion and development of individual papers, this call invites advanced doctoral students and early postdocs from all disciplines concerned with creativity and uncertainty to join our discussion in Berlin. The working language will be English.
Applications
The deadline for applications is October 15, 2018. Applicants are requested to email a CV and a short essay (max. 2,000 words including references) to konstantin.hondros@uni-due.de. This short essay should summarize the research that is to be presented during the Spring School. Notification of acceptance is sent out no later than October 30, 2018. In case of acceptance, a revised longer paper – either an extended essay (max. 4,000 words) or a full paper (max. 8,000 words) – must be sent by January 15 2019 for distribution to discussants and workshop participants well in advance of the event.
Formats
Later-stage full papers are presented in Presentation Sessions (20 minutes for presentation, followed by 10 minutes for feedback from renowned scholars and 10 minutes for open discussion); earlier-stage work and short papers are discussed in Group Discussions consisting of three or four early scholars and two discussants (5 minutes for presentations followed by everyone at the round table, providing feedback based on their advance reading of the paper and for open discussion).
Practical information
There is a participation fee of € 100, but several grants for travel expenses will be available. The workshop will be held at the Department of Management of Freie Universität Berlin. We start our Spring School with a kick-off event on March 12 at 6 p.m., our closing discussion on March 15 will conclude the School at 1 p.m.
For further information about the project ‘Organized Creativity’:
what problems do people think antitrust is going to solve?
Last week, I asked why antitrust is having a moment (it’s continued, on Planet Money and elsewhere), and why Democrats are using radical language to make fairly modest proposals. In this post, I’m going to ask what problems people think antitrust is going to solve, anyway.
Certainly a lot of the current concern about antitrust comes from a broad sense that corporations are too economically and politically powerful, that our economy has been restructured in ways that make ordinary people worse off, and that massive tech companies are able to use our data in ways that we have little control over. That’s political antitrust. And those are totally real issues.
But I want to explore some new questions being raised that are not exactly within the current scope of economic antitrust, but that are still kind of speaking its language—that are pushing to change the antitrust technocracy, not up-end it. To recap, as it has been construed for the last thirty-plus years, the purpose of antitrust is to promote consumer welfare, generally by trying to keep firms from being able to raise and keep prices above a competitive level. The focus is consumers, and prices.
Increasingly, though, people at least adjacent to the space of antitrust expertise are making claims about economic problems they think are being caused by lax antitrust enforcement, or that antitrust should be addressing. And those proposals are worth keeping an eye on, because as hard as it might be to change the expert consensus, it’s still more likely than a new anti-monopoly movement. (Though the two could certainly reinforce each other.) I see these new arguments as falling into basically three categories.
Market power has effects we didn’t realize
Market power is the ability to keep prices above a competitive level (i.e. above marginal cost). Once upon a time, people thought there was a fairly close relationship between how concentrated a market is—that is, how many companies control what share of the market—and how much market power firms have. Since the 1970s, there has been much less of a presumption that concentration, on its own, indicates market power. That means that there’s been less concern about whether we’ve got four airlines controlling 70% of the U.S. market, or that four carriers control 99% of the U.S. wireless market.
Increasingly, though, people are raising flags about other problems that might result from market power. One of these is labor monopsony—the idea that firms have market power, but as purchasers of labor, not sellers of products, and that this is driving wages down. The Council of Economic Advisers put out a report last fall suggesting this might be happening, and Democrats’ mention of “bargaining power for workers” implies this is part of what they’re trying to address. There are related arguments about market power in supply chains and the emergence of “winner take most” industries that also suggest links between concentration or market power and wages.
In theory, monopsony can be handled within the current legal framework, though it is rarely addressed in practice. So developing arguments about the effects of market power on workers, and a legal framework for addressing that within antitrust, is one conceivable new direction for antitrust.
Others are arguing that market power can lead firms to attach undesirable conditions to products that make them lower quality, even as price remains the same. In particular, some scholars, including Nobel Laureate Joe Stiglitz, have framed privacy as an antitrust issue: the product may be free, but consumers have no choice about how their data is used (and in the case of platforms like Facebook, no equivalent competitors). Privacy is hard to address within a framework focused purely on price. But in Europe, competition policy is increasingly tackling privacy issues, and Germany is currently investigating whether Facebook’s dominant position is forcing consumers to give up their privacy without having an alternative choice.
Market power has causes we didn’t realize
The Atlantic just featured a story with the dramatic title, “Are Index Funds Evil?” The article discusses the rise of large institutional investors—index funds, though not only index funds—and what it means that, increasingly, big chunks of competitors in a specific market are actually owned by the same few corporations. It goes on to discuss work by José Azar, Martin Schmalz, and Isabel Tecu that finds that this common ownership enhances market power, and that airline ticket prices are 3-7% higher than they would be under separate ownership.
In this story, index funds were the hook, but it just as easily could have been framed around antitrust. In a way, common ownership was the original antitrust question: the big trusts of the late 19th century were not single-firm monopolies, but competitors that had turned over ownership to a group of trustees that made unified governance decisions. And while research in this area is still new and findings tentative, legal scholars are already making the case that antitrust law can cover the anticompetitive effects of these horizontal shareholdings. If this work continues to hold up, this seems potentially transformative.
Technological change is creating new threats to competition
Finally, a fair bit of the recent chatter is basically arguing, “it’s the technology, stupid.” The dynamics of competition change as more of the economy shifts to online platforms. Because of network effects, companies like Facebook, Google, Apple, and Amazon are hard to compete with—much of their value comes from their existing user base. And because they aren’t just selling products to consumers, but connecting consumers with producers, they aren’t acquiring market power in the traditional sense. Facebook and Google are free products, after all.
But the power of network effects means that they have a tendency towards monopoly. And the fact that the four largest companies by market capitalization are platforms suggests how central platforms have become to our economy.
So we have these new companies that have become very large, and that appear monopolistic, though they also create great value for consumers. From an antitrust perspective, they don’t really appear to be a problem, because they aren’t raising prices. And the history of rapid technological change over the past 25 years, including the rise and fall of a number of once-dominant platforms, raises the question of whether even platforms behaving in anticompetitive ways pose much of a long-term threat.
Recent scholarship, though, argues that monopolistic platforms are in fact anticompetitive, that it is a problem, and that current law is poorly equipped to handle. Lina Khan’s much-circulated note in the Yale Law Journal, for example, argues that 1) platforms encourage predatory pricing—generally seen as irrational (and thus not an issue) within antitrust law—because network effects encourage pursuit of growth over profit, and 2) platforms collect data on rivals that give them an unfair competitive advantage. These sorts of issues clearly fit within the broad scope of “protecting competition,” but don’t fit easily with a consumer welfare, market power conception of antitrust.
Changing that would be a significant project, but if we have an economy that is dominated by firms whose potentially anticompetitive activity is essentially beyond the scope of antitrust, there’s not much left to antitrust. And again, the massive fine the E.U. just levied on Google—for favoring its own shopping service, consisting of companies that pay Google to be on it, over competitors in search results—suggests what this could look like. So far, the U.S. has not demonstrated much enthusiasm about expanding antitrust in this direction. But it’s not inconceivable that it could happen, and it could be done within a framework that was focused solely on competition, if not only on consumer welfare.
Again, all these challenges to the current antitrust framework are at least in the ballpark of its conversation, even if they would require pushing the law in new directions or advancing the acceptance of new economic theories. And they are not the only arguments that are in play here. For example, the question of whether inequality is facilitated by concentration or market power, or whether it has become such a central economic problem that antitrust should try to address it, have prompted enough discussion that two leading antitrust scholars have felt the need to argue that antitrust should leave inequality alone.
Unlike political antitrust, which would probably require a social movement to move it forward, these antitrust arguments have the potential to gain traction without necessarily requiring legislation or a revolution against the current antitrust regime. The 1970s shift toward Chicago-style antitrust happened, to a considerable extent, because the old economic framework seemed increasingly inadequate for explaining the world people found themselves in. As the current framework comes to seem similarly dated, this could be another moment when such change is possible.
conspiracy theory, donald trump, and birtherism: a new article by joe digrazia
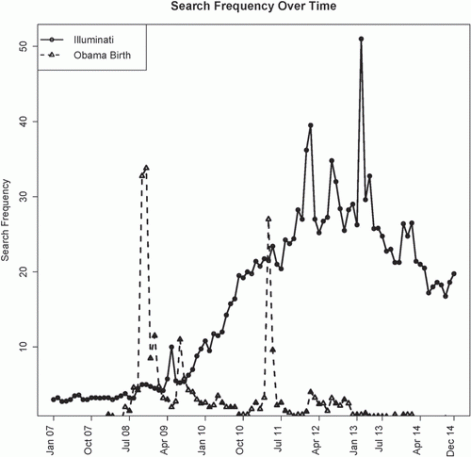
Joe DiGrazia, a recent IU PhD and post-doc at Dartmouth, has a really great article in Socious, the ASA’s new online open access journal. The article, The Social Determinants of Conspiratorial Ideation, investigates the rise in conspiratorial thinking on the Internet. He looks at state level Google searches for Obama birtherism and then compares to non political types of conspiracy theory, like Illuminati.
The findings? Not surprisingly, people search for conspiracy related terms in places with a great deal of social change, such as unemployment, changes in government, and demographic shift. This is especially important research given that Donald Trump first rose to political prominence as a birther. This research is indispensable for anyone trying to understand the forces that are shaping American politics today.
50+ chapters of grad skool advice goodness: Grad Skool Rulz ($5 – cheap!!!!)/Theory for the Working Sociologist/From Black Power/Party in the Street
book highlight: Digital Kenya
Now is the time of year when we are wading through the flotsam of the passing semester (grading, entering grades, firefighting “emergency” cases, etc.) and preparing for the next semester (more of the same?).
Nonetheless, a new semester always brings the prospect of joining the cutting edge…

For those of you looking to update syllabi or reading lists on technology and organizations, have a look at Bitange Ndemo and Tim Weiss‘s co-editted new book Digital Kenya: An Entrepreneurial Revolution in the Making (2016, Palgrave), which with the support of the Ford Foundation is (bonus alert!) also available as an open access PDF.

The book’s press release (digitalkenyapressrelease_december2016-final) promises insiders’ perspectives of what it takes to launch and sustain organizations in a growing tech sector. Its conversations with social entrepreneurs and founders of leading organizations rounds out research that is usually conducted of high-tech firms in North America. For example, in conversation #3, Anne Githuku-Shongwe explains how she founded Afroes to counter negative Western stereotypes with positive images of heroes and heroines for her children. In conversation #6, Su Kahumbu Stephanou, creator of the mobile App iCow, recounts her journey, along with various setbacks, towards sustainable, organic farming.

For the open access publication, visit www.tinyurl.com/DigitalKenya-free.
To order the book in print, visit www.tinyurl.com/DigitalKenya.
amazon won’t destroy college as we know it
I’m really bad at keeping up with the media cycle.
So last Wednesday, Vox put up this cute piece with the catchy title, “How Amazon Could Destroy College as We Know It.” Written in the form of a letter from Jeff Bezos to shareholders in the year 2030, it tells the story of how Amazon came to supplant traditional higher education by developing, and selling at cost, badges that people could earn to demonstrate particular skill sets. As the value of badges became evident, companies became more and more interested in using them in hiring—to the detriment, presumably, of traditional indicators like college degrees.
It’s a clever article, and well-written. It also doesn’t quite make the claim the headline implies—that the rise of Amazon badges would destroy higher education. Nevertheless, although I think that the piece gets at something real that is going on, and that is eventually going to be an important source of change, this is not how I see it going down.
Anyway, Wednesday night I started writing a blog post using a similar Bezos-to-shareholders conceit, but from a 2030 that looked quite different. It just wasn’t quite working, I think because it’s hard to see Amazon pioneering the kind of change I can imagine. Pearson, maybe. But even I can’t name the CEO of Pearson. (Apparently it’s John Fallon.)
So the format wasn’t quite working, but the underlying point still nagged. While badges may become a thing, and perhaps Amazon may even pioneer them, they are not going to be “the” new form of educational currency. The world in which “as many as half of major US employers now consider Amazon badges to be one of their top five criteria when determining whom to hire” will remain a fantasy.
arthur c clarke describes the internet in 1974
50+ chapters of grad skool advice goodness: Grad Skool Rulz ($2!!!!)/From Black Power/Party in the Street
pricing the priceless parking spot
Planet Money had a fun podcast a couple of days ago about Eric Meyer, the young founder of Haystack, a Baltimore-based app that allowed people to auction off their (public) parking spot to the highest bidder. MonkeyParking, a similar app, got attention last year in San Francisco.
The founders, in both cases, focused on the time-saving, traffic, and environmental benefits of such an app. Clearly there are real costs to people spending long periods of time circling the block in search of parking. UCLA economist Donald Shoup has argued that 30% of traffic in central business districts results from people looking for parking.
But these apps quickly generated enormous hostility. People used words like “disgusting,” “evil” and called it “JerkTech”—all to the apparent surprise of Meyer, at least. Within months, Boston and San Francisco had passed ordinances forbidding the selling of public parking spots. Haystack and MonkeyParking were basically shut down by the end of the year. (MonkeyParking has since retooled as a way to sell the parking in your driveway.)
This is a familiar story to economic sociologists. Some area of life that was previously outside of the market is suddenly brought into it. Violent feeling erupts, as such transactions are seen to challenge the moral order. (See Zelizer, Healy, Quinn, Chan, etc.) Generally, the market wins, and morality adapts.
There aren’t too many things—humans, organs (though even that’s eroding)—where a bright line still forbids buying and selling. Why, then, do Haystack and similar apps generate such hostility?
I think there are a couple of independent things prompting the hostile reaction.
1. Something that was, at least superficially, free, suddenly comes to cost money. People really don’t like being charged for things that used to be free, even if they were always paying for it somehow. (See: airline fees.)
2. Someone is making money by selling public property. This one is probably more important to city officials than city residents. From this perspective, the problem isn’t selling the spot, but who’s receiving the gains. Indeed, some of the same cities that reacted so negatively to these apps (I’m looking at you, San Francisco) have introduced dynamic pricing of parking, which allows prices to fluctuate with demand. (Think: Uber surge pricing.)
3. Now only the well-off can afford to park. This objection is to my mind the most legitimate. And while I fully recognize that it is really wasteful to have people circling around looking for parking, I don’t think it can easily be dismissed.
Now, I don’t want to stake any big claims around the inalienable right of Americans to park their cars. After all, you have to have a certain amount of money to have a car in the first place. And in general I think policies that discourage driving are good.
And it’s the very basis of capitalism to accept that there are things that some people can afford and others can’t, and to make one’s peace with that. But the thing about price caps (whether the cap is zero, as for street parking, or some flat rate, as with taxicabs) is that while they are inefficient, they are also democratizing. Yes, you may have to circle the block for 20 minutes. But dammit, so do the tech entrepreneurs who are pricing you out of your apartment. There are some things you can’t buy your way out of.
We live in a society in which inequality continues grow. At the same time, technology is improving our ability to make people who are willing (and able) to pay a lot do just that. That may be efficient. But it further reduces the sense that we’re all in this game together. And that’s the issue we don’t have a good solution for.
what’s really important about the arizona state mooc announcement
Arizona State has been in higher ed news a lot this week. The Atlantic just published a fairly fawning article on ASU’s partnership with Starbucks, featuring trenchant critiques of traditional colleges like, “The customer service is atrocious.”
Today, the news is ASU’s announcement that it will offer its entire freshman year online, through MOOCs. (Just when you thought they were dead!) Here’s the deal: ASU is partnering with EdX, the nonprofit Harvard-MIT collaboration, to produce the MOOCs. Students don’t have to apply, and they don’t have to pay in advance. But after they complete the class, if they decide they want college credit, they can pay ASU $300-600 (the final price is not set) and it will show up on a transcript indistinguishable from any other class.
Of course, people love to hate on ASU president Michael Crow. Dean Dad pointed out that Maricopa Community College, in ASU’s backyard, only charges $250 a credit and provides library access, among other amenities. John Warner focuses on the importance of the first year to student persistence, implying that disadvantaged students will be hurt. Jonathan Rees amps up the rhetoric, calling ASU the first “predator university.”
The Chronicle’s analysis focuses on what it sees as the catch: ASU’s MOOC students won’t be eligible for financial aid. Because students won’t officially enroll until after they’ve completed the MOOC, what they’ve learned is considered “prior knowledge,” making them ineligible for federal aid. ASU admits this is an obstacle, but suggested that “the university hoped to find some way to make aid possible in the future.”
What the Chronicle doesn’t point to, though, is where this road ultimately leads. There’s no way ASU is committing to this if it doesn’t see a pathway to federal aid down the road. Who among the underemployed folks ASU is targeting can cough up $600 to pay for a single course? That’s more than two weeks’ work at minimum wage.
And indeed, noises about how to solve this problem are already being made. Conversations are underway in the Senate about finding ways to give accreditation — and thus access to aid — to “nontraditional providers” like (drumroll…) EdX.
Truthfully, I’m not that worried about ASU and EdX. I think it’s going to prove hard to get the disadvantaged students they’re aiming for to finish MOOCs, even with financial aid, and even with ASU’s well-publicized innovations in data analytics. And I think that the nonprofit EdX, with its close ties to Harvard and MIT, is unlikely to launch a race to the bottom in extracting revenues from students.
But you know who would be happy to suck at the teat of the federal financial aid system? The edutech disruptors, who talk a good game about transforming higher education but will quickly enough start tranforming student loans into company profits once it’s time to raise the next round of venture capital.* When we have the opportunity to channel our financial aid dollars not only to the University of Phoenix but to the Disruptive EduBadge Academy, then we will have fully corrupted the system. The reason, if it needs to be spelled out, is that there is no reason to think that their courses will require learning, that pesky obstacle between them and those tantalizing financial aid dollars.
I’m not anti-technology, or anti-innovation. And I think traditional colleges are deeply flawed. But I am very, very much against expanding the money-laundering side of our financial aid system. And that is the coal mine into which the ASU-EdX canary is being lowered.
—
* I just Googled “silicon valley edutech” and got the San Francisco EduTech Meetup Group for — you can’t make this stuff up — “connecting folks who are passionate about the education space.”
driverless cars and the end of death
In my course in introductory sociology, I have a module on health. One lecture describes the leading causes death, across age groups and across time periods. In modern times, one of the leading causes of death is “unintentional injury.” What does that mean? Roughly speaking, the three major categories of unintentional injury death are, in order, falling, auto accidents, and accidental poisoning.
The interesting thing is that these are all types of death that relate to economic development: cars, chemical, tall buildings, stairs and so forth. The other side is that economic development can also help us out. For example, in about one generation, driverless cars will be widespread. The implication is that drunk driving will be eliminated over night and accidents relating to drifting driver attention will disappear overnight. Truck accidents should also disappear. My hypothesis is that computer driven cars will probably be better than most people when they drive in the rain or snow. They might even automatically shut down if conditions are bad enough.
Bottom line: Economic development has unintended consequences. Sometimes they are bad, such as auto related deaths. But development can introduce solutions. The driverless car will be one such example.
50+ chapters of grad skool advice goodness: Grad Skool Rulz ($2!!!!)/From Black Power/Party in the Street!!
more (angry) tweets, more heart attacks
PS Magazine reports on research that links tweet sentiment and health:
Measuring such things is tough, but newly published research reports telling indicators can be found in bursts of 140 characters or less. Examining data on a county-by-county basis, it finds a strong connection between two seemingly disparate factors: deaths caused by the narrowing and hardening of coronary arteries and the language residents use on their Twitter accounts
…
“Given that the typical Twitter user is younger (median age 31) than the typical person at risk for atherosclerotic heart disease, it is not obvious why Twitter language should track heart disease mortality,” writes a research team led by Johannes Eichstaedt and Hansen Andrew Schwartz of the University of Pennsylvania. “The people tweeting are not the people dying. However, the tweets of younger adults may disclose characteristics of their community, reflecting a shared economic, physical, and psychological environment.”
Not a puzzle to me. I have argued that social media content is often an indicator – a smoke signal – of other trends. Thus, if people are stressed due to environmental conditions (the economy, unemployment), they will have heart attacks and write angry text. The only question is when the correlation holds. For more discussion of the more tweets/more votes/more anything phenomena, click here.
50+ chapters of grad skool advice goodness: Grad Skool Rulz ($1!!!!)/From Black Power/Party in the Street!!
more tweets, more votes: it works for TV!!!

Within informatics, there is a healthy body of research showing how social media data can be used for forecasting future consumption. The latest is from a study by Nielsen, which shows some preliminary evidence that Twitter activity forecasts television program popularity. In their model, adding Twitter data increases the explained variance in how well a TV show will in addition to data on promotions and network type. Here’s the summary from Adweek.
50+ chapters of grad skool advice goodness: Grad Skool Rulz ($1!!!!)/From Black Power/Party in the Street!!
zeynep tufekci and brayden king on data and privacy in the new york times
My co-bloggers are on a roll. Zynep Tufekci and Brayden King have an op-ed in the New York Times on the topic of privacy and data:
UBER, the popular car-service app that allows you to hail a cab from your smartphone, shows your assigned car as a moving dot on a map as it makes its way toward you. It’s reassuring, especially as you wait on a rainy street corner.
Less reassuring, though, was the apparent threat from a senior vice president of Uber to spend “a million dollars” looking into the personal lives of journalists who wrote critically about Uber. The problem wasn’t just that a representative of a powerful corporation was contemplating opposition research on reporters; the problem was that Uber already had sensitive data on journalists who used it for rides.
Buzzfeed reported that one of Uber’s executives had already looked up without permission rides taken by one of its own journalists. Andaccording to The Washington Post, the company was so lax about such sensitive data that it even allowed a job applicant to view people’s rides, including those of a family member of a prominent politician. (The app is popular with members of Congress, among others.)
Read it. Also, the Economist picked up Elizabeth and Kieran’s posts 0n inequality and airlines.
50+ chapters of grad skool advice goodness: Grad Skool Rulz/From Black Power
this is not a post about ello
This is not a post about Ello. Because Ello is so last Friday. But the rapid rise of and backlash against upstart social media network Ello (if you haven’t been paying attention, see here, here, here) reminded me of something I was wondering a while back.
Lots of people are dissatisfied with Facebook — ad-heavy, curated in a way the user has little control over, privacy-poor. And it looks like Twitter, which really needs bring in more revenue, is taking steps to move in the same direction: algorithmic display of tweets, with the ultimate goal of making users more valuable to advertisers.
The question is, what’s the alternative? There have been a lot of social network flavors of the month, built on a variety of business models. Some of them, like Google Plus, are owned by already-large companies that would be subject to similar business pressures as Facebook and Twitter. Others, like Diaspora (remember Diaspora?), were startups with an anti-Facebook mission (privacy, decentralization), but collapsed under the weight of their own hype.
I can’t imagine that a public utility model would work for a social network — I just don’t see “government-owned” and “fast-moving technological change” going together successfully. But I keep wondering why a Wikipedia model couldn’t work. Make it a 501(c)3. Attract some foundation funding — it’s a pro-democracy project. Solicit gifts from pro-privacy people in the tech industry — there are lots of those. Then once it’s off the ground, ask users for donations.
Sure, there is the huge, huge hurdle of getting enough of a network base to attract new users. But it seems like the costs should not be insane. If it only takes 200 employees to run Wikipedia, as large as it is, how many would it take to get a big social network off the ground? Facebook employs 7000, but a lot of them have to be in the business of figuring out how to sell Facebook.
Maybe there have been (failed) efforts like this and I just haven’t noticed. Or maybe the getting-the-user-base issue is really insurmountable. But it seems like if a real Facebook alternative is to emerge, it can’t just be from a corporate competitor (e.g. Google), and the startup/VC model (e.g. Ello) is going to be susceptible to all the same problems as it grows. Why not a different model?
sample computer science/sociology syllabus
Loyal orgtheorista and sociologist Amy Binder has forwarded me this course syllabus for a course at UC San Diego. It is called Soc 211 Computational Methods in Social Science and was taught by Edward Hunter and Akos Rona-Tas. The authors are working on a textbook, the course was made open to a wide range of students, a and it was supported by the Dean at UCSD. I heard people had a nerdy good time. Click here to read the soc211_syllabus.
50+ chapters of grad skool advice goodness: Grad Skool Rulz/From Black Power
why the facebook/okcupid conversation needs the history of technology
I’m in the Poconos this week with old college friends and only intermittently paying attention to the larger world. And I’m hesitant to opine about the latest in the world of online experimentation (see here, here, or here) because honestly, it’s not my issue. I don’t study social media. I don’t have deep answers to questions about the ethics of algorithms, or how we should live with, limit, or reshape digital practices. And plenty of virtual ink has already been spilled by people more knowledgeable about the details of these particular cases.
But I do want to make the case that it’s important to have this conversation at this particular moment. Here is why:
If there’s one thing the history of technology teaches us, it’s that technology is path-dependent, and as a particular technology becomes dominant, the social and material world develop along with it in ways that have a lasting impact.
The QWERTY story, in which an inefficient keyboard layout was created to slow down the users of jam-prone typewriters but long outlasted those machines, may be apocryphal. Perhaps a better example is streetcars.
Historian Kenneth Jackson, in the classic Crabgrass Frontier, showed how U.S. cities were first reshaped by streetcars. Streetcars made it possible to commute some distance from home to work, and helped give dense, well-bounded cities a hub-and-spokes shape, with the spokes made up of rail lines. This was made possible by new technology.
Early in the 20th century, another new technology became widely available: the automobile. The car made suburbanization, in the American sense involving sprawl and highways and a turn away from center cities, possible.
But the car alone was not enough to suburbanize the United States. Jackson’s real contribution was to show how technological developments intersected with 1) cultural responses to the crowded, dirty realities of urban life, and 2) government policies that encouraged both white homeownership and white flight, to create the diffuse, car-dependent American suburbs we know and love. The two evolve together: technological possibilities and social decisions about how to use the technologies. As they lock in, both become harder to change — until the next disruptive technology (((ducking))) comes along.
So what does all this have to do with OKCupid?
The lesson here is that technologies and their uses can evolve in multiple ways. European cities developed very differently from American cities, even though both had access to the same transportation technologies. But there are particular moments, periods of transition, when we start to lock in a set of institutions — normative, legal, organizational — around a developing new technology.
We’re never going to be able to predict all the effects that a particular social decision will have on how we use some technology. Government support of racist red-lining practices is one reason for the white flight that encouraged suburbanization. But even if the 1930s U.S. mortgage policy hadn’t been racist, other aspects of it — for example, making the globally uncommon fixed-rate mortgage the U.S. norm — still would have promoted decentralization and encouraged the car-based suburbs. Some of that was probably unforeseeable.*
But some of it wasn’t. And I can’t help but think that more loud and timely conversation about the decisions and nondecisions the U.S. was making in the early decades of the 20th century might have led the country down a less car-dependent path. Once the decisions are made, though, they become very difficult to change.
Right now, it is 1910. We have the technology to know more about individuals than it has ever been possible to know, and maybe to change their behavior. We don’t know how we’re going to govern that technology. We don’t really know what its effects will be. But this is the time to talk about the possibilities, loudly and repeatedly if necessary. Maybe the effects on online experimentation will turn out to be to be harmless. Maybe just trusting that Facebook and OKCupid aren’t setting us on the wrong path will work out. But I’d hate to think that we unintentionally create a new set of freedom-restricting, inequality-reproducing institutions that look pretty lousy in a few decades just because we didn’t talk enough about what might — or might not — be at stake.
“That’s how websites work” isn’t a good enough answer. If 62% of Facebook users don’t even know there’s an algorithm, there’s plenty of room for conversation.
—
* There is a story that GM drove the streetcars out of business by buying up streetcar companies and then dismantling the streetcars. There are a number of accounts purporting to debunk this story. This version, which splits the difference (GM tried, but it wasn’t a conspiracy, and it was only one of several causes) seems knowledgeable, but I’d love a pointer to an authoritative source on GM’s role.
how much to quantify the self?
Over at Scatterplot, Jeremy’s been writing about his life gamification experiment, which involves giving himself points for various activities he’d like to be doing more of. I find this sort of thing totally compelling and have to admit I’m now giving myself all sorts of points in my head. (Finish unpacking one box — 5 points! Send an email I’ve been procrastinating on — 5 points!) Although not in 100 million years could I get my husband to play along with me, even for brunch, of which he is fond.
Anyway, the game brought to mind this post from Stephen Wolfram, in which Wolfram presents a bunch of data from the last 25 years of his life. Here, for example, are all the emails he’s sent since 1989. (Note the sharp time shift in 2002, when he stopped being completely nocturnal.) He’s also got keystroke data, times of calendar events, time on the phone, and physical activity.

Fascinating to read about, but perhaps not terribly healthy to pursue in practice. Although in Wolfram’s case, it sounds like he was mostly just collecting the data, not using it to guide his day-to-day decisions. Others become more obsessive. I don’t know if David Sedaris has really been spending nine hours a day walking the English countryside, a slave to his Fitbit, or if he’s taking poetic license, but it’s a heck of an image.
Clearly there are a lot of people into this sort of thing. In fact, there is a whole Quantified Self movement, complete with conferences and meet-up groups. One obvious take on this is that we’re all becoming perfect neoliberal subjects, rational, entrepreneurial and self-disciplined.
For me, though, what is fun and appealing as a choice — and I do think it’s a choice — becomes repellent and dehumanizing when someone pushes it on me. So while I’ll happily track my work hours and tally my steps just because I like to — and yes, I realize that’s kind of weird — I hate the idea of judging tenure cases based on points for various kinds of publications, and am uneasy with UPS’s use of data to ding drivers who back up too frequently.
It’s possible that I’m being inconsistent here. But really, I think it’s authority I have the problem with, not quantification.
on facebook and research methods
Twitter is, well, a-twitter with people worked up about the Facebook study. If you haven’t been paying attention, FB tested whether they could affect people’s status updates by showing 700,000 folks either “happier” or “sadder” updates for a week in January 2012. This did indeed cause users to post more happy or sad updates themselves. In addition, if FB showed fewer emotional posts (in either direction), people reduced their posting frequency. (PNAS article here, Atlantic summary here.)
What most people seem to be upset about (beyond a subset who are arguing about the adequacy of FB’s methods for identifying happy and sad posts) is the idea that FB could experiment on them without their knowledge. One person wondered whether FB’s IRB (apparently it was IRB approved — is that an internal process?) considered its effects on depressed people, for example.
While I agree that the whole idea is creepy, I had two reactions to this that seemed to differ from most.
1) Facebook is advertising! Use it, don’t use it, but the entire purpose of advertising is to manipulate your emotional state. People seem to have expectations that FB should show content “neutrally,” but I think it is entirely in keeping with the overall product: FB experiments with what it shows you in order to understand how you will react. That is how they stay in business. (Well, that and crazy Silicon Valley valuation dynamics.)
2) This is the least of it. I read a great post the other day at Microsoft Research’s Social Media Collective Blog (here) about all the weird and misleading things FB does (and social media algorithms do more generally) to identify what kinds of content to show you and market you to advertisers. To pick one example: if you “like” one thing from a source, you are considered to “like” all future content from that source, and your friends will be shown ads that list you as “liking” it. One result is dead people “liking” current news stories.
My husband, who spent 12 years working in advertising, pointed out that this research doesn’t even help FB directly, as you could imagine people responding better to ads when they’re happy or when they’re sad. And that the thing FB really needs to do to attract advertisers is avoid pissing off its user base. So, whoops.
Anyway, this raises interesting questions for people interested in using big data to answer sociological questions, particularly using some kind of experimental intervention. Does signing a user agreement when you create an account really constitute informed consent? And do companies that create platforms that are broadly adopted (and which become almost obligatory to use) have ethical obligations in the conduct of research that go beyond what we would expect from, say, market research firms? We’re entering a brave new world here.
twitter publics
The first “tweets/votes” paper established the basic correlation between tweet share and vote share in a a large sample of elections. Now, we’re working on papers that try to get a sense of who is driving the correlation. A new paper in Information, Communication, and Society reports on some progress. Authored by Karissa McKelvey, Joe DiGrazia and myself, “Twitter publics: how online political communities signaled electoral outcomes in the 2010 US house election” argues that the tweet-votes correlation is strongest when people compose syntactically simple messages. In other words, the people online who use social media in a very quotidian way are a sort of “issue public,” to use a political science term. They tend to follow politics and the talk correlates with the voting, especially if it is simple talk. We call this online audience for politics a “twitter public.” Thus, one goals of sociological research on social media is to assess when online “publics” act as a barometer or leading indicator of collective behavior.
50+ chapters of grad skool advice goodness: From Black Power/Grad Skool Rulz
world wide heavy metal
My good friend Jeffrey Timberlake and his MA student Adam Mayer have a forthcoming paper on the world wide diffusion of heavy metal (early version here). It is coming out in Sociological Perspectives:
The purpose of this paper is to explain the timing and location of the diffusion of heavy metal music. We use data from an Internet archive to measure the population-adjusted rate of metal band foundings in 150 countries for the 1991–2008 period. We hypothesize that growth in “digital capacity” (Internet and personal computer use) catalyzed the diffusion of metal music. We include time-varying controls for gross national income, political regime, global economic integration, and degree of metal penetration of countries sharing a land or maritime border with each country. We find that digital capacity is positively associated with heavy metal band foundings, but, net of all controls, the effect is much stronger for countries with no history of metal music prior to 1990. Hence, our results indicate that increasing global digital capacity may be a stronger catalyst for between-country than for within-country diffusion of cultural products.
My inner Beavis yearns to come out.
50+ chapters of grad skool advice goodness: From Black Power/Grad Skool Rulz
the new computational sociology conference – sign up today!
This coming August 15, Dan McFarland of Stanford University and I will host a conference on the new computational sociology at the Stanford campus. The goal is to bring together social scientists, informatics researchers, and computer scientists who are interested in how modern computation can be brought to bear on issues that are of central importance to sociology and related disciplines. Interested people should go to the following web site for information on registration and presentation topics. I hope to see you there.
50+ chapters of grad skool advice goodness: From Black Power/Grad Skool Rulz
three visiting fellowships on innovation at the Technische Universitat in Berlin – due Feb. 15, 2014
One of our orgtheory readers, Jan-Peter Ferdinand, forwarded a flier about a fellowship opportunity at the Technische Universität in Berlin, Germany. This sounds like a great opportunity for grad students and prospective post-docs who are studying innovation.
Here’s an overview:
The DFG graduate school “Innovation society today” at the Technische Universität Berlin, Germany, is pleased to advertise 3 visiting fellowships. The fellowships are available for a period of three months, either from April to June 2014 or October to December 2014.
The graduate school addresses the following key questions: How is novelty created reflexively; in which areas do we find reflexive innovation; and which actors are involved? Practices, orientations, and processes of innovations are studied in and between various fields, such as (a) science and technology, (b) the industrial and service sectors, (c) arts and culture, and (d) political governance, social planning of urban and regional spaces. More information about the graduate school can be found on our website: http://www.innovation.tu-berlin.de (click on the flag at the top of the page for an English version).By following an extended notion of innovation, the graduate school strives to develop a sophisticated sociological view on innovation, which is more encompassing than conventional economic perspectives. Our doctoral students are currently undertaking a first series of case studies to promote a deeper and empirically founded understanding of the meaning of innovation in contemporary society and of the social processes it involves.
See this PDF (GW_Ausschreibung-2014) for more info, including deadline (Feb. 15, 2014) and application materials needed.
a sociologist working at facebook
Michael Corey is a PhD candidate in sociology at the University of Chicago. This guest post explains his experiences working for Facebook, the world’s leading social networking website (as if you didn’t know that!).
Another Dispatch from Industry
Last summer I moved from Chicago to the bay area to work as a quantitative researcher at Facebook. I’d done six years in the PhD program at Chicago and left with drafts of all my dissertation papers but without a cohesive dissertation to turn in (3 paper dissertations aren’t exactly allowed). Six months at Facebook has been eye opening and weird. Below I’ll try to give readers a feel for what it is like to go from an academic track to an industry job.
The FB Culture:
The culture at Facebook is really fun. I work at the main campus in Menlo Park, where a few thousand people work on the various FB platforms and the associated companies (Parse, Onavo, Instagram, etc). My mother-in-law describes it as an Oxford College designed by Willy Wonka, which is pretty fair. The campus houses everything you need to reduce any external friction that would take you off-campus during the day [http://cnettv.cnet.com/barber-candy-shop-bank-among-deluxe-perks-facebook/9742-1_53-50153870.html]. It is pretty easy to drink the Kool-Aid about how great FB is, and I would imagine that it is hard to work here if you don’t. I wasn’t the biggest FB user when I started here, but having been off the site for a long time I learned to recognize how much I missed by not being on it. For so many of my peers it is the only medium to communicate news, baby pictures, or cat memes to weak ties. Risk taking is encouraged and speed is considered a virtue.
university of chicago visit – everything you wanted to know about tweets and votes, but were afraid to ask
![]()
I will be a guest of the computational social science workshop at the University of Chicago this coming Friday. I will present a very detailed talk on the more tweets/more votes phenomena called “Everything You Wanted to Know About the Tweets-Votes Correlation, but Were Afraid to Ask.” If you want to chat or hang out, please email me.
Refreshments will be served.
50+ chapters of grad skool advice goodness: From Black Power/Grad Skool Rulz
b-school org change syllabi bleg
To my brothers and sisters in the business schools:
I am interested in masters/doctoral level syllabi on the topic of organizational change, especially with a strategic management emphasis. Please provide links or email me directly. Much appreciated.
Adverts: From Black Power/Grad Skool Rulz
best art installation of the year?
From rAndom International. Amazing.
Adverts: From Black Power/Grad Skool Rulz
The Golden Age of LISREL
Jim Moody and I are writing an article on data visualization in Sociology. Here’s a picture that won’t be in the final version, but I like it all the same.

waiting for big data to change my world
I keep hearing about the coming big data revolution. Data scientists are now using huge data sets, many produced through online interactions and media, that shed light on basic social processes. Big data data sets, from sources like Twitter, Facebook, or mobile phones, give social scientists ways to tap into interactions and cultural output at a scale that has never been seen before in social science. The way we analyze data in sociology and organizational theory are bound to change due to this influx of new data.
Unfortunately, the big data revolution has yet to happen. When I see job candidates or new scholars present their research, they are mostly using the same methods that their predecessors did, although with incremental improvements to study design. I see more field experiments for sure, and scholars seem more attuned to identification issues, but the data sources are fairly similar to what you would have seen in 2003. With a few notable exceptions, big data have yet to change the way we do our work. Why is that?
Last week Fabio had a really interesting post about brain drain in academia. One reason we might see less big data than we’d like is because the skills needed to handle this type of analysis are rare and much of the talent in this area is finding that research jobs in the for-profit world are more lucrative and rewarding than what they’re being offered in academia. I believe that’s true, especially for the kinds of people who are attracted to data mining techniques. The other problem though, I think, is that social scientists are having a hard time figuring out how to fit big data techniques into the traditional milieu of social science. Sociologists, for example, want studies to be framed in a theoretically compelling way. Organizational theorist would like scholars to use data that map on to the conceptual problems of the field. It’s not always clear in many of the studies that I’ve read and reviewed that big data analyses are doing anything new other than using big data. If big data studies are going to take over the field they need to address pressing theoretical problems.
With that in mind, you should really read a new paper by Chris Bail (forthcoming in Theory and Society) about using big data in cultural sociology. Chris makes the case that cultural sociology, a subfield that is obsessed with understanding the origins of and practical uses of meaning, is prime for a big data surge. Cultural sociology has the theoretical questions, and big data research offers the methods.
More data were accumulated in 2002 than all previous years of human history combined. By 2011, the amount of data collected prior to 2002 was being collected very two days. This dramatic growth in data spans nearly every part of our lives from gene sequencing to consumer behavior. While much of these data are binary and quantitative, text-based data is also being accumulated on an unprecedented scale. In an era of social science research plagued by declining survey response rates and concerns about the generalizability of qualitative research, these data hold considerable potential. Yet social scientists – and cultural sociologists in particular – have ignored the promise of so-called ‘big data.’ Instead, cultural sociologists have left this wellspring of information about the arguments, worldviews, or values of hundreds of millions of people from internet sites and other digitized texts to computer scientists who possess the technological expertise to extract and manage such data but lack the theoretical direction to interpret their meaning in situ….[C]ultural sociologists have made very few ventures into the universe of big data. In this article, I argue inattention to big data among cultural sociologists is particularly surprising since it is naturally occurring – unlike survey research or cross-sectional qualitative interviews – and therefore critical to understanding the evolution of meaning structures in situ. That is, many archived texts are the product of conversations between individuals, groups, or organizations instead of responses to questions created by researchers who usually have only post-hoc intuition about the relevant factors in meaning-making – much less how culture evolves in ‘real time’ (note: footnotes and references removed).
Chris goes on to offer suggestions about how cultural sociology might use big data to address big theoretical questions. For example, he believes that scholars studying discursive fields would be wise to use big data methods to evaluate the content of such fields, the relationships between actors and ideas, and the relationships between different fields. Of course, much of the paper is about how to use big data analysis to enhance or replace traditional methods used in cultural sociology. He discusses how Twitter and Facebook data might supplement newspaper analysis, a fairly common method in cultural and political sociology. Although he doesn’t go into great detail about how you would do it, an implicit argument he makes is that big data analysis might replace some survey methods as ways to explore public opinion.
I continue to think there is enormous potential for using big data in the social sciences. The key for having it accepted more broadly is for data scientists to figure out how to use big data to address important theoretical questions. If you can do that, you’re gold.
more tweets, more votes – but why?

In the More Tweets, More Votes paper, we established that Twitter share correlates with future Congressional election results (e.g., % of tweets that mention GOP in a district correlates with the GOP vote share in the district). The deeper question – why? We’ve got a working paper that suggests an answer: Twitter, in some respects, mimics conventional text, which means that is close enough to the grass roots. In other words, people are more likely to use technology if it resembles what they know – an idea going back to a classic paper by Kwon and Zmud.
We can tease out testable implications. Specifically, technologies that are more sophisticated will be less likely to correlate with mass politics. In others, social media that is easy to use and relies mainly on pre-existing language skills are more likely to correlate with social trends than social media that require higher levels of functionality.
We test this with our tweets/votes data. We measured three types of candidate tweet share – “free text,” @mentions, and #hashtags. Free text is the “people’s” method of tweeting, while @mentions and #hashtags are syntaxes that require more knowledge. The grassroots hypothesis implies free text mentions of candidates will have a stronger correlation with election outcomes than @mentions or #hashtags. The results? Free texts correlate (as per the original paper) but the others are not significantly different from zero. The picture says it all.
Stark result. The implication is profound for social scientific studies of social media. If your data requires distinctly Internet based skills, it is less likely to speak to population level trends. Sophistication is probably the mark of connoisseur. Indeed, additional analysis of our data shows that @mention and #hashtag users are “intense” Internet users. For example, they have bigger median followers and are more likely to be “verified” by Twitter.
Adverts: From Black Power/Grad Skool Rulz
codefellas
From David Rees/WIRED magazine.
Adverts: From Black Power/Grad Skool Rulz
kieran on slate today
Kieran has a satirical piece on Slate today: Using Metadata to Find Paul Revere. Check it out.
Adverts: From Black Power/Grad Skool Rulz
did the internet just kill the constitution?
Last week, it was revealed that the NSA collects important data about all Verizon phone calls and has access to the servers of most major Internet firms like Facebook and Google. Of course, this sort of behavior is exactly what civil rights activists had warned about for years.
But there is a deeper lesson – the Internet has made it remarkably easy for the Federal government to collect enormous amounts of information on many aspects of our lives. If the reports are to be believed, the Prism program, which allows the Feds to search Internet firms, costs only $20 million. I can’t imagine the downloading of Verizon data can’t be that much more expensive. When communication was mainly done through voice and paper, this simply was not possible at the same scale.
So it has come to this. The Internet gives us cheap and easy communication, but it also makes a low cost copy of everything that third parties can hold onto, whether we like it or not. It is clear that the Courts, Congress, and the President aren’t in a rush to make sure that searches are done for probable cause. As I type this, President Obama asserts that it’s ok because they can’t hear your calls, but they just know who you are calling all the time. It’s not clear to me that there is anything that will reverse the erosion of privacy in the Internet age.
Adverts: From Black Power/Grad Skool Rulz
a twiggle – all possible tweets
Definition: Given a set of X characters, a twiggle is the total possible number of tweets, or X^140. Since most English speakers will use the ASCII characters, one standard English twiggle is 95^140:
76,085,997,811,183,562,98,135,408,710,
751,483,265,995,839,561,200,415,768,
293,251,897,463,276,887,905,308,084,
750,663,238,388,192,091,262,455,112,
983,664,085,632,015,778,607,866,277,
286,667,119,278,691,334,591,691,395,
102,241,018,148,609,396,820,768,967,
497,516,903,602,766,888,745,368,135,
114,497,853,537,865,999,264,122,596,
201 ,787,018,799,223,005,771,636,962,
890,625
This was computed using the Online Long Number Calculator.
Adverts: From Black Power/Grad Skool Rulz
